
Figure 1

Figure 2
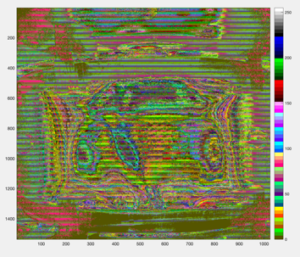
Figure 3
Data compressor is one key issue for storing and transmitting large dataset. Data compression algorithm based on the usage of different length code for integer representation may be effective only if output stream is tightly packed. Hardware realization of these procedures has definite advantages in comparison with the software execution. For example many fast video-cameras have high performance CMOS sensor technology usually adopted for acquiring and store scientific images. Typical use cases are in the field of nuclear fusion experiments with plasmas magnetically confined on which fast camera acquiring and store images of plasma discharges. A Photron FASTCAM SA4 camera has been in operations in ENEA on Frascati Tokamak Upgrade and Proto-Sphera tokamak experiments. The FASTCAM SA4 camera provides up to 3600 frames/s at 1024×1024 pixel resolution collected on 12-bit depth image. SA4 is supplied with 16 GB memory option, hence it can capture all the frames in the ~2 s of plasma discharge at the maximum performance of 3600 fps, 1024×1024 pixel resolution. The camera downloads 9.5 GB for each plasma discharge of raw uncompressed data with image processing software able to convert in standard format like “tif” (fig.1). The raw data acquired with a digital camera like SA4 is a measure of the radiant intensity which refers to the magnitude or quantity of light energy actually reflected from or transmitted through the object being imaged by an analog or digital device. it is the only variable that can be utilized by processing techniques in quantitative scientific experiments as shown the fig.2 with a different colors scale. The 12-bit pixel depth image, associated to the huge amount of data produced by the SA4 camera, poses a problem of storage versus data integrity. In fact, due to the fact that the smallest addressable unit in a digital processor is a byte, to preserve data information it would be necessary to save each pixel in a two-byte format, thus getting a 25% storage overhead. The alternative could be compression, but this would cause undesirable data loss. In order to save both storage space and data integrity, a Bit-Packing compression algorithm operating at bit level, has been developed to reduce the number of bit requested to store 12-bit raw data of SA4 camera. Roughly speaking, the Bit-Packing algorithm maps two 12-bit pixels to three 8-bit pixels. In this specific compression domain, Bit-Packing is one of the most frequently applied compression schemes. However, (de)compression should not come with any additional cpu load during run time, but should be provided as fast as possible and efficiently in terms of energy consumption. To achieve that target, the development of a Bit-Packing algorithm for Field Programmable Gate Arrays (FPGAs) is a candidate solution aware with the aims of the TEXTAROSSA project.
For more than 20 years, High-Level Synthesis (HLS) has been widely investigated and studied as a way to raise the level of abstraction in programmable electronic system design, allowing SW developers to design dedicated computing architectures to be implemented on top of the FPGA (Field Programmable Gate Array) technology.
The advantages of FPGAs come from:
– the huge parallelism available: thousands of DSP modules and millions of small programmable LUT allow to implement designs able to sustain hundreds of GFlop/s – or several TOp/s, if we refer to simpler limited precision fixed-point arithmetic
– the high internal memory bandwidth: thousands of independent small block RAMs allow to achieve an internal memory bandwidth of several TB/s, needed to sustain the high computing performance potentially achievable thanks to the huge HW parallelism
– the availability of IP (Intellectual Properties) blocks, on the same FPGA silicon, that implement Arm processor cores, PCIe and memory controllers, and high-speed communication links, …
– the low power consumption (few tens of watts)
Despite previous advantages, FPGA adoption in the HPC community has been quite limited, mainly because their programming required HW design expertise. To overcome this limitation, HLS flows play a fundamental role as they allow to define the behavior of the system to be synthesized by means of high-level languages such as C/C++, Matlab, SYCL, …
In the past years, the maturity of HLS flows has been the main limitation to their widespread diffusion: the quality of the produced HW was poor (the efficiency was low), the integration of the algorithm accelerated in HW with other parts running on conventional host computers was sometimes cumbersome, the reprogramming of FPGA was a problem, often requesting a new reboot of the system to detect the new HW.
We are now in a phase where HLS flows seem to have reached their maturity: there are HLS flows (like the Vitis from Xilinx or OneAPI from Intel) that allow obtaining quite an efficient parallel and pipelined implementation of a design (even if still some consciousness of the architecture to be generated is required to the SW programmer that can control through pragmas the compiler behavior and the structure of the generated HW), taking care of low-level details as the different clock domains, offering simple syntax to manage the communications and synchronization among different kernels, giving access to a wide set of pre-implemented IP and computing libraries. HLS flows use the partial reprogramming capabilities of FPGAs and allow the interface shell (i.e., the PCIe, memory, and all the I/O interfaces) to be not reprogrammed each time, being kept fixed and solving the rebooting problem. Furthermore, modern HLS flows come with run-time support that allows the simple and efficient integration between the application running in the host and the accelerated kernels running on the FPGA.
In TEXTAROSSA project one of the main aim is the software development for an FPGA accelerator using an HLS flow (namely, Vitis) neglecting the low-level FPGA details of the Xilinx Alveo U280 in operation at ENEA FPGA LAB in Portici.
A kernel function implementing the BitPacking algorithm delete the four leading bits in the pixel components of each image from an input stream resulting in a compressed image on the output stream.
If m and n are the numbers of bits used to store a component of an NxN image, the input image has dimension mN^2/8 [Byte] and the output image nN^2/8 [Byte], so the compression ratio is m/n; we indicate with S the size, in bit, of the input and output streams of the kernel; S is constrained to be a power of 2. In the beginning, input and output images are aligned with respect to S, i.e., both the input and output streams have a pixel component starting at bit 0 of the input/output; to determine how many components must be read to be aligned again both at the input and the output streams, we must find the smallest number of pixel components k∈ℕ+ satisfying the following equation (% is the modulus operator):
(k * m) % S = (k * n) % S (1)
From (1) it is easy to verify that the solution is:
k=LCM(LCM(m,S)/m,LCM(n,S)/n) (2)
Where LCM(a,b) returns the Least Common Multiple of the a and b. In our case we set the stream size S=512 bits (thus saturating the PCIe bandwidth in the reasonable hypothesis to use fck=300 MHz), m=16 bits and n=12 bits; the expression (2) gives k=128. As we read from the stream S bits, data are newly aligned after k m/S=4 reads from the input stream and k * n/S=3 writes to the output stream. From previous computations, we derive the structure of the Bit-Packing compression function:
for (i=0; i<InputImageSize/S; i+= km/S) {
read km/S words from the input stream;
while (not all the input bits have been copied) {
copy n bits from the input word to the output word;
skip (n-m) bits of the input word;
}
write the kn/S words that have just been filled;
}
The Bit-Packing compressed image of fig.2 is depicted in the fig.3.
Benchmarking sessions are ongoing in order to evaluate Time and Energy to Solution within the WP1 and WP4 activities of TEXTAROSSA.
Leading Partner: ENEA
People: Francesco Iannone, Paolo Palazzari