One of the aims of the TEXTAROSSA project is to define and develop a stream-based programming paradigm able to integrate vertically with the heterogeneous TEXTAROSSA node.
Towards this activity the TEXTAROSSA project leverages the FastFlow [1] C++ header-only library which provides application designers abstractions for parallel programming (e.g., Pipeline, ordered Task-Farm, Divide & Conquer, Parallel-For-Reduce, Macro Data-Flow) and a carefully designed run-time system. At the lower layer, the library defines so-called Building Blocks (BB), i.e., recurrent data-flow compositions of concurrent activities working in a streaming fashion, which represent the primary abstraction layer to build FastFlow parallel patterns and streaming topologies [2, 3]. A parallel application is conceived by adequately selecting and assembling a small set of BBs modelling data and control flows. The BBs can be combined and nested in different ways forming either acyclic or cyclic concurrency graphs, where nodes are FastFlow concurrent entities and edges are communication channels.
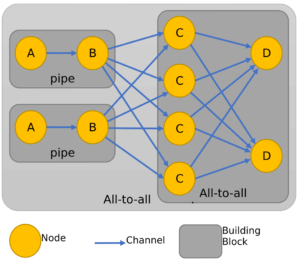
Figure 1: Example of a FastFlow application: the communication topology is described as a composition of building blocks in a data-flow graph.
Within the project the aim is to extend FastFlow with a new offloader node able to delegate the computation to an FPGA accelerator hosted on the TEXTAROSSA node. This is done by programmatically loading the desired compute kernel onto the FPGA and streaming the input/output data to/from the FPGA accelerator. This will allow to have FastFlow applications which leverage seamlessly heterogeneous compute resources by simply using traditional nodes, using CPU threads, and offloader nodes, delegating work to accelerators, in the same concurrency graph.
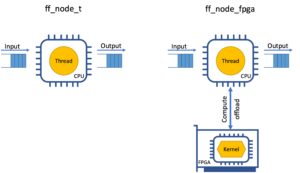
Figure 2: FastFlow node comparison: Traditional vs. Offloader.
The main challenge in designing the offloader node is how to maximize the performance gain from using the accelerator card. Indeed, while the accelerator is expected to compute the results of the compute kernel substantially faster than the CPU, the communication with the card causes extra delays. The aim is to design schemes which can minimize/hide the impact of the extra time needed to send/receive data from the accelerator card.
Works Cited
[1] M. Aldinucci, M. Danelutto, P. Kilpatrick and M. Torquati, “FastFlow: High-level and Efficient Streaming on Multi-core,” in Programming Multi-core and Many-core Computing Systems, John Wiley & Sons, Ltd, 2017, pp. 261-280.
[2] T. Massimo, Harnessing Parallelism in Multi/Many-Cores with Streams and Parallel Patterns, University Of Pisa, 2019.
[3] M. Aldinucci, S. Campa, M. Danelutto, P. Kilpatrick and M. Torquati, “Design patterns percolating to parallel programming framework implementation,” International Journal of Parallel Programming, vol. 42, no. 6, pp. 1012-1031, 2013.
Leading Partner: CINI/UNITO